服务器节点
Storm的集群表面上看和hadoop的集群非常像。但是在Hadoop上面你运行的是MapReduce的Job, 而在Storm上面你运行的是Topology。
它们是非常不一样的 — 一个关键的区别是:一个MapReduce Job最终会结束, 而一个Topology运永远运行(除非你显式的杀掉他)。
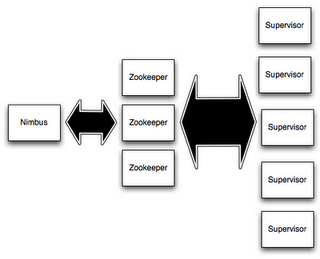
在Storm的集群里面有两种节点:控制节点(master node)和工作节点(worker node)。
控制节点上面运行一个后台程序:Nimbus,它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分布代码,分配工作给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。
每一个工作进程执行一个Topology的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程组成。
Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。
并且,nimbus进程和supervisor都是快速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面,要么在本地磁盘上。
这也就意味着你可以用kill -9来杀死nimbus和supervisor进程, 然后再重启它们,它们可以继续工作,就好像什么都没有发生过似的。
这个设计使得storm不可思议的稳定。
数据流
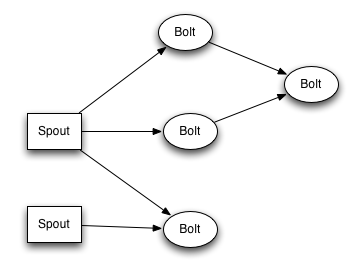
stream是storm里面的关键抽象。一个stream是一个没有边界的tuple序列。storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream。
比如: 你可以把一个tweets流传输到热门话题的流。
storm提供的最基本的处理stream的原语是Spout和Bolt。你可以实现Spout和Bolt对应的接口以处理你的应用的逻辑。
Spout的流的源头。比如一个spout可能从kafka队列里面读取消息并且把这些消息发射成一个流。
又比如一个spout可以调用twitter的一个api并且把返回的tweets发射成一个流。
Bolt可以接收任意多个输入stream,作一些处理,有些bolt可能还会发射一些新的stream。
一些复杂的流转换,比如从一些tweet里面计算出热门话题,需要多个步骤,从而也就需要多个bolt。
Bolt可以做任何事情: 运行函数,过滤tuple,做一些聚合,做一些合并以及访问数据库等等。
spout和bolt所组成一个网络会被打包成topology,topology是storm里面最高一级的抽象,你可以把topology提交给storm的集群来运行。